I thought it would be appropriate today, on the 40th anniversary of discovery of the problem, to address the issue of Halloween protection. Describing the problem is nothing new, of course, but nonetheless, I thought it would be interesting to illustrate in my own words.
Reportedly, the Halloween problem was identified on October 31, 1976 by three researchers, and the name stuck. Imagine that we have a table of employees with salary information. We’ll create such a table and make the employee name the primary key and the clustering key, and then put a nonclustered index on salary. Here is such a table with some random data.
create table Employee ( FirstName nvarchar(40) not null, Salary money not null, constraint pk_Employee primary key clustered (FirstName) ); create nonclustered index ix_Employee__Salary on Employee (Salary); insert Employee (FirstName, Salary) values ('Hector', 22136), ('Hannah', 21394), ('Frank', 28990), ('Eleanor', 29832), ('Maria', 28843), ('Maxine', 23603), ('Sylvia', 26332), ('Jeremy', 20230), ('Michael', 27769), ('Dean', 24496); |
The task at hand is to give all employees with a salary of less than 25,000 a 10% raise. This can be accomplished with a simple query.
update Employee set Salary = Salary * 1.10 where Salary < 25000.00; |
Now imagine that the SQL Server optimizer decides to use the nonclustered index to identify the rows to update. The index initially contains this data (bearing in mind that the index implicitly contains the clustering key).
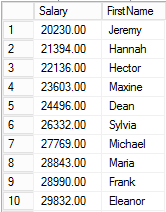
Without Halloween protection, we can imagine that SQL walks through the rows in the index and makes the updates. So the Jeremy row is updated first, and the new salary is 22,253.
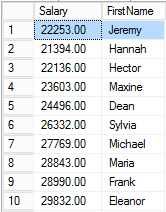
However, the index is keyed by Salary and should be sorted on that column, so SQL Server will need to move the row in the index to the appropriate location.
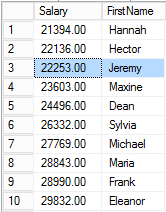
Next, SQL updates the Hannah row and moves it within the index.
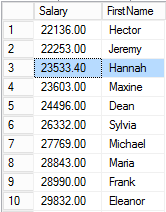
And then for Hector:
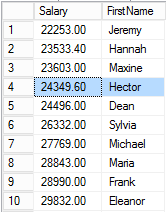
However, at this point, the next row is Jeremy again. So the database updates the Jeremy row for a second time.
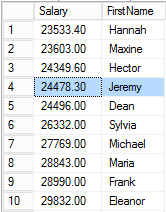
Hannah again.
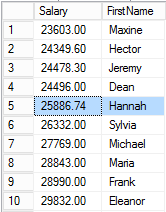
Then Maxine.
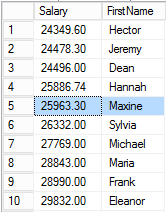
Finally Hector for a second time, followed by Jeremy for a third time, and then Dean.
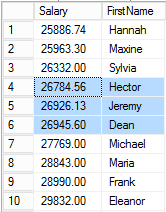
At this point the next row is for Hannah again. However, her salary is greater than or equal to 25,000 and therefore doesn’t qualify for update based on the query predicate. Since none of the remaining rows meet the WHERE clause condition, processing stops and query execution is complete.
That, in a nutshell, is the Halloween problem: some rows get process multiple times as a result of the row being physically moved within the index being used to process the query. For comparison, the (incorrect) results described the above processing are on the left, and the correct results are on the right.
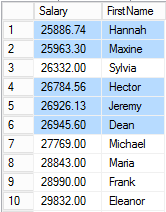
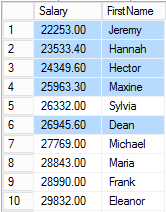
In this particular case, the process results in every employee having a salary of at least 25,000. However, imagine if the query didn’t have the WHERE clause but still chose to use the Salary index to process. The result would be an infinite loop where each employee’s salary would be repeatedly increased by 10% until an overflow condition occurred.
So how does SQL Server protect against the Halloween problem? There are a variety of mechanisms in place for this very purpose.
- SQL Server may choose an alternate index. In fact, this is precisely what SQL will do in our example by reading from the clustered index to drive the updates. Because the clustered index isn’t sorted by Salary in any way, updates during the processing phase don’t affect the row location and the problem does not arise. This separation of the read and write portion avoids the problem.

- But what if scanning the clustered index is a relatively expensive operation. When I load 1,000,000 rows into the Employee table and only 5 employees have salaries below 25,000, SQL Server will naturally favor the nonclustered index.

Note particularly the highlighted Sort operator. Sort is a blocking operation, that is, the entire input set must be read (and then sorted) before any output is generated. Once again, this separates the read and write phases of query processing.
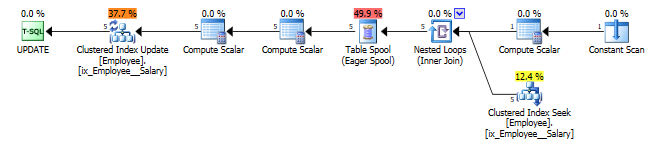
- Suppose that the Salary index is the only means of access the data. For instance, if I drop the nonclustered Salary index and the primary key on the table, and then create a clustered index on Salary, SQL Server is forced to use the Salary index. In this case, SQL Server will insert an eager spool into the plan, once again separating the reading and writing.
- Memory-optimized (Hekaton) tables avoid the Halloween problem by their very nature. Rows in a memory table are read-only, and “updates” to the row cause the current version of the row to be invalidated a new version of the rows to be written. Once again, read and write separation happens, in this case organically.
I don’t intend this to be a comprehensive list of protections in SQL Server, but it covers the most common scenarios.
To me, the key takeaway here is that Halloween protection is an integral and crucial aspect of query processing that the optimizer simply must take into account. This most certainly affects the plan generation processes and likely adds overhead to the plan to ensure correct results.
